El extraño caso de la IA: cada vez está más barata, y cada vez estamos pagando más que nunca por usarla

Cada vez que ChatGPT genera una palabra, eso cuesta dinero. Pero el precio de esa palabra generada no ha parado de caer desde el lanzamiento de ese modelo, y lo mismo ocurre con sus rivales. Hoy en día tenemos modelos de IA que no solo son más potentes, sino que además son más baratos que nunca, y lo curioso es que estamos pagando cada vez más por usarlos. ¿Qué está pasando?
Tokens. OpenAI define los tokens como "secuencias comunes de caracteres que se encuentran en un conjunto de texto". Esa "unidad básica" de información es la que usan estos modelos para entender qué estamos diciendo y luego procesar esos textos para respondernos. Cada vez que usamos ChatGPT tenemos por un lado la petición con el texto que introducimos (tokens de entrada) y por el otro el texto generado por el chatbot (tokens de salida).
|
Precio por millón de tokens (Dólares) |
Entrada |
Salida |
|---|---|---|
|
GPT-5 |
1,10 |
10 |
|
GPT-4o |
2,5 |
10 |
|
o1 |
15 |
60 |
|
Gemini 2.5 Pro (<200k tokens) |
1,25 |
10 |
|
gemini 2.5 Pro (>200Ktokens) |
2,5 |
15 |
|
Claude opus 4.1 |
15 |
75 |
|
Claude sonnet 4 (< 200k tokens) |
3 |
15 |
|
Claude sonnet 4 (> 200k tokens) |
6 |
22,5 |
Precio por millón de tokens. Y cuando usamos un modelo de IA, el precio de usarlo precisamente se mide en cuánto cuesta cada millón de tokens de entrada y cada millón de tokens de salida. Cuanto más potente es un modelo, más alto es el precio de esos tokens, y para hacernos una idea estos son los precios de algunos modelos actuales. Los precios de los tokens de salida (los generados por las máquinas) son notablemente más altos que los de entrada: cuesta mucho más generar texto que "recibirlo y entenderlo".
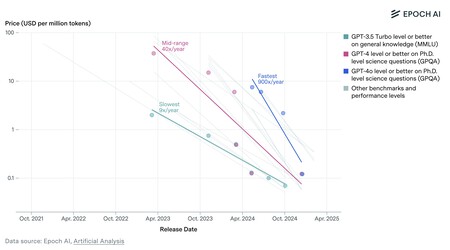 Los modelos de IA son cada vez mejores y cada vez más baratos. Al menos, en cuanto a coste por millón de tokens. Fuente: Epoch AI.
Los modelos de IA son cada vez mejores y cada vez más baratos. Al menos, en cuanto a coste por millón de tokens. Fuente: Epoch AI.Pero los precios no han parado de bajar. Esos precios por millón de tokens de entrada o salida, no obstante, han caído de forma notable desde que ChatGPT (en aquel momento basado en GPT-3.5) apareció en escena. Un estudio de Epoch AI de marzo de 2025 revelaba como el precio de la inferencia —generar texto, como hacen ChatGPT, Gemini o Claude— no ha parado de caer. En algunos casos los modelos son más pequeños y eficientes, y además el hardware también es ahora más rentable, lo que favorece esa caída de precios.
Y aún así pagamos cada vez más por usar la IA. Sin embargo los desarrolladores que usan estos modelos de IA para programar se están dando cuenta de que sus facturas son cada vez más altas. Este tipo de profesionales han sido los que de momento más han aprovechado las ventajas de esta tecnología, pero al hacerlo se han dado cuenta de esa contradicción. En realidad la explicación es sencilla.

Razonar gasta muchos tokens. El problema está en que los modelos de razonamiento consumen muchísimos tokens. Este tipo de tecnología mejora la precisión de las respuestas, pero para lograrlo los modelos no paran de "pensar" y generar distintas teorías para luego analizarlas y quedarse con la solución que consideran más probable o mejor. Los modelos que "no piensan" y generan texto "solo una vez" consumen pocos tokens, pero los que "razonan" multiplican ese coste de forma notable.
El vibe coding sale caro. El ejemplo más caro de esos elevados costes de la IA lo tenemos en las plataformas de "vibe coding". Con ellas es posible programar casi sin saber programar, pero estas herramientas hacen un uso extensísimo de los modelos de IA, y ahí el consumo de tokens (sobre todo, los de salida, que son los más caros) se dispara. Varias empresas de este segmento, como Windsurf o Cursor, se han dado cuenta de lo difícil que es ganar dinero con la IA, y hay también diversos usuarios que están alertando de esos costes disparados en Reddit, por ejemplo.
Y los agentes de IA prometen ser muy caros. Se espera que los agentes de IA sean capaces de hacer muchas cosas por nosotros, pero estos sistemas serán caros porque consumirán también muchísimos tokens para entender, "razonar" y llegar a la solución deseada.
Solución: usar IAs que no piensen tanto. Frente a esas IAs que "razonan" y consumen muchos costes, la alternativa es clara: no recurrir tanto a los modelos de razonamiento y en su lugar optar por modelos que "no razonan" para abaratar costes. Estos modelos son mucho más baratos de usar y pueden ser útiles para multitud de escenarios. Afortunadamente también han aparecido modelos de IA eficientes y cada vez más baratos que razonan: DeepSeek R1 es una buena prueba de ello.
El famoso enrutador quizás no sea mala idea. Cuando OpenAI lanzó GPT-5 lo hizo con su célebre "router" o "enrutador" que analizaba la petición y decidía por sí solo qué variante del modelo (más o menos potente) debía contestar a la pregunta. Como vimos, ese enrutador tiende a optar por usar el modelo "barato", pero eso no es mala idea. Ni para OpenAI (a quien le cuesta mucho menos procesar la respuesta) ni para los usuarios (que también consumen menos recursos y tienen más cuota libre para otras preguntas que quizás sí necesiten "razonamiento").
Imagen | Levart Photographer | Igal Ness
En Xataka | Los agentes de IA son prometedores. Pero como en el FSD de Tesla, mejor no quitar las manos del volante
-
La noticia El extraño caso de la IA: cada vez está más barata, y cada vez estamos pagando más que nunca por usarla fue publicada originalmente en Xataka por Javier Pastor .
Fuente: Xataka
Enlace: El extraño caso de la IA: cada vez está más barata, y cada vez estamos pagando más que nunca por usarla
Comentarios
Publicar un comentario